From data lake to flexible data lakehouse













Many companies and organizations have invested large sums of money in data warehousing (DWH) over the past few decades. In recent years, however, DWHs have fallen somewhat into disrepute for being cumbersome and complex obstacles on the road to data-driven organizations, rather than accelerating the journey there. Data Lakes have long been hoped to take the pressure off DWHs and make them more agile. Here and there, the end of data warehousing has already been proclaimed, but a data lake alone does not replace a structured data warehouse. Only since the emergence of so-called “lakehouses", which combine the advantages of DWHs and data lakes, has there been a real alternative to the DWH. According to the principle "from data lake to flexible data lakehouse", or is this just a DWH in a new guise? That's what we want to find out in this article.
One thing is clear: The business requirements that led to the development of DWHs are still relevant and even more urgent. Reporting and data analysis should increasingly be possible in real time, and data must be understandable, findable, and documented - especially for advanced analytics.
In this article, we want to focus on data storage. The requirements from the business translate into specific technical requirements on how data is to be collected and processed.
Let's take a look at which of these technical requirements are
- a classic data warehouse, with structured relational data, versus
- a classic data lake, i.e., essentially a file store
can cover:
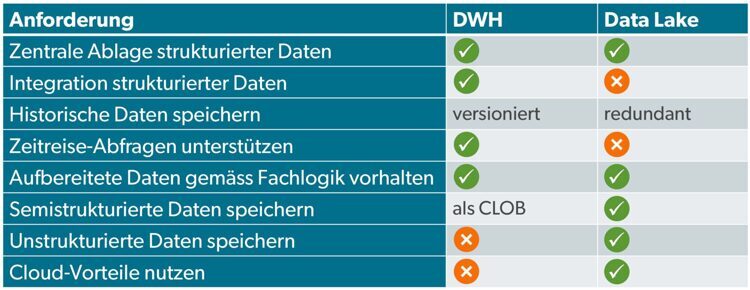
While classic DWHs cannot take full advantage of today's cloud capabilities (scalability, billing based on usage) and allow only insufficient options for integrating and evaluating semi-structured and unstructured data, they offer established methods for integrating and modeling structured data and, above all, elegant historization options so that time travel becomes possible. This refers to the retrieval of data in the form in which it existed at a specific point in time in the past. This is a key requirement in many applications. Such historization techniques of a DWH additionally support error tracking and recoverability of data, which can often be of great benefit in ongoing operations.
To enable time travel via a data lake, all historical data would have to be stored redundantly, i.e., a complete copy of the data would have to be available for each day, for example, with historization on a daily basis. Since data lakes are merely file stores, once data has been stored it can no longer be changed (in a performant manner) with pinpoint accuracy, but only supplemented. Data management therefore becomes a major challenge without further support.
A DWH, on the other hand, is usually based on a relational database. Thus, a DWH uses some functionalities that the pure data lake lacks:

The data and the data structures of a DWH can be specifically queried and changed with SQL - the files in a data lake cannot be so far. This possibility of targeted querying and modification is central for robust ETL or ELT processes for data integration and for efficient historization, i.e., for core tasks of data collection.
The first Data Lakes often became "swamps" (Data Swamps), because they were seen only as data storage for mass data that no longer fit into the DWH. Recently, however, data lakes have been supplemented by components with the above-mentioned functionalities. This is how the "Data Lakehouse" came into being. The essential components of a data lakehouse are:
- A cloud-based object store, which is usually S3-compatible, is used as the data store. Structured data is stored in open (i.e., non-proprietary), query-optimized file formats such as Parquet or Apache Iceberg.
- To manage the data structures with which the data can be queried, "Hive" has become the de facto standard for metadata. Hive supports versioning of the data structures (schema evolution) and uses a relational database (ideally also cloud-based) as the storage location for the metadata.
- The most important component in Lakehouse is the query engine. It enables the query and targeted modification of the data with SQL. It should support Hive as well as the open-source file formats mentioned above to avoid vendor lock-in. Dremio and Presto are example technologies for this, while DeltaLake uses a proprietary file format.
As in the DWH, these central components are supplemented by a variety of other technologies, whether for data management (ELT processes), data catalogs, or reporting.
Whereas in the classic DWH a single technology - the (usually proprietary) relational database - is responsible for several functionalities, in the lakehouse this is replaced by several individual technologies. However, these use compatible standards at their interfaces so that they are interchangeable, thus eliminating dependence on a single manufacturer. In combination, the optimized file formats and the query engines ensure that the functions of the DWH are also available on a data lake.
The advantages of the new architecture are:
- Data can be stored independently of the query technology (query engine) thanks to the open formats. It is therefore possible to replace the query engine without changing the data structures. Supplementary technologies (data catalogs, ETL tools, etc.) can also be freely selected. As a result, vendor lock-in is reduced.
- The cloud capabilities, especially scalability and usage-based billing, become fully usable. The size of the data store and the performance of the queries can also be scaled separately - those who have a lot of data, but simple queries pay less.
- Semi-structured and unstructured data can be stored in the same location as structured data, facilitating centralized governance.
- Thanks to the central data repository with its open interfaces, the connection of new data sources is simplified. This gives analysts faster access to new raw data, while it can be refined for other target groups later or as needed.
With its open interfaces, the Data Lakehouse also sets itself apart from cloud data warehouses such as Snowflake, which rely more heavily on proprietary technologies.
A data lakehouse can replace a DWH. But if a data lakehouse does the same thing as a DWH, only with different technologies, will it be as cumbersome as (supposedly) the DWH?
Let's look at the DWH best practice of storing data in multiple layers: The first layer contains the raw data as delivered: separated by source systems, but already historized. The second layer contains cleansed and integrated data, and a third layer delivers technically prepared data optimized for visualization or OLAP. The layers thus contain redundant data, and whenever data (or data structures!) are changed, all layers must be updated. If one considers the necessary quality assurance and documentation, it becomes clear why changes in the DWH are tedious and comparatively costly in many organizations.
However, neither the historization of raw data, nor its cleansing and integration, nor the introduction of business logic in the data lakehouse are superfluous. It is still important to automate these data management processes as extensively as possible. The higher data layers should be created in such a way that, in the event of errors or the need for changes, they can be reconstructed without too much effort from the lowest layer, which should already be historized. These tasks can already be solved today, but thanks to its open basic structures, the ecosystem of lakehouses is likely to further fuel technology competition here and make even more standard data management tasks easier in the future.
One example of this is the "Infrastructure as Code" approach, as used in the Eraneos Data Hub. The basic framework for data management in the cloud is provided extremely quickly with this platform - even for a data lakehouse. This allows data professionals to concentrate on their core tasks and immediately benefit from the advantages of the cloud without first having to wait for time-consuming installation work.

Conclusion
New technologies, cloud standards and open interfaces are fueling the competition between technologies in the data lakehouse. There are already prefabricated lakehouse architectures that can be set up in the cloud almost at the push of a button, such as the Eraneos Data Hub.
A data lakehouse can replace a data warehouse, but the historization of data, professional refinement and visualization remain tasks that data engineers have to deal with. No one is spared professional data management.
Managing many different data silos is not only inefficient, but also leads to redundancies and high costs. This paper is currently only available in German.
Digital Platforms | Enabler of an agile enterprise architecture
The e-paper series "Digital Platforms - Enabler of an Agile Enterprise Architecture" sheds light on the design of business applications based on digital platforms.The e-papers are currently only available in German.
Every company has large amounts of data in which valuable business-relevant knowledge lies dormant. Our data science specialists can help you extract and utilize this knowledge.
We have compiled reports on our projects, interesting facts from the various competence and customer areas as well as information about our company for you here.